Einleitung
Auf dieser Seite wird der Ablauf von der Erhebung der Daten für das Projekt bis hin zur Visualisierung der Ergebnisse beschrieben.
Datengrundlage
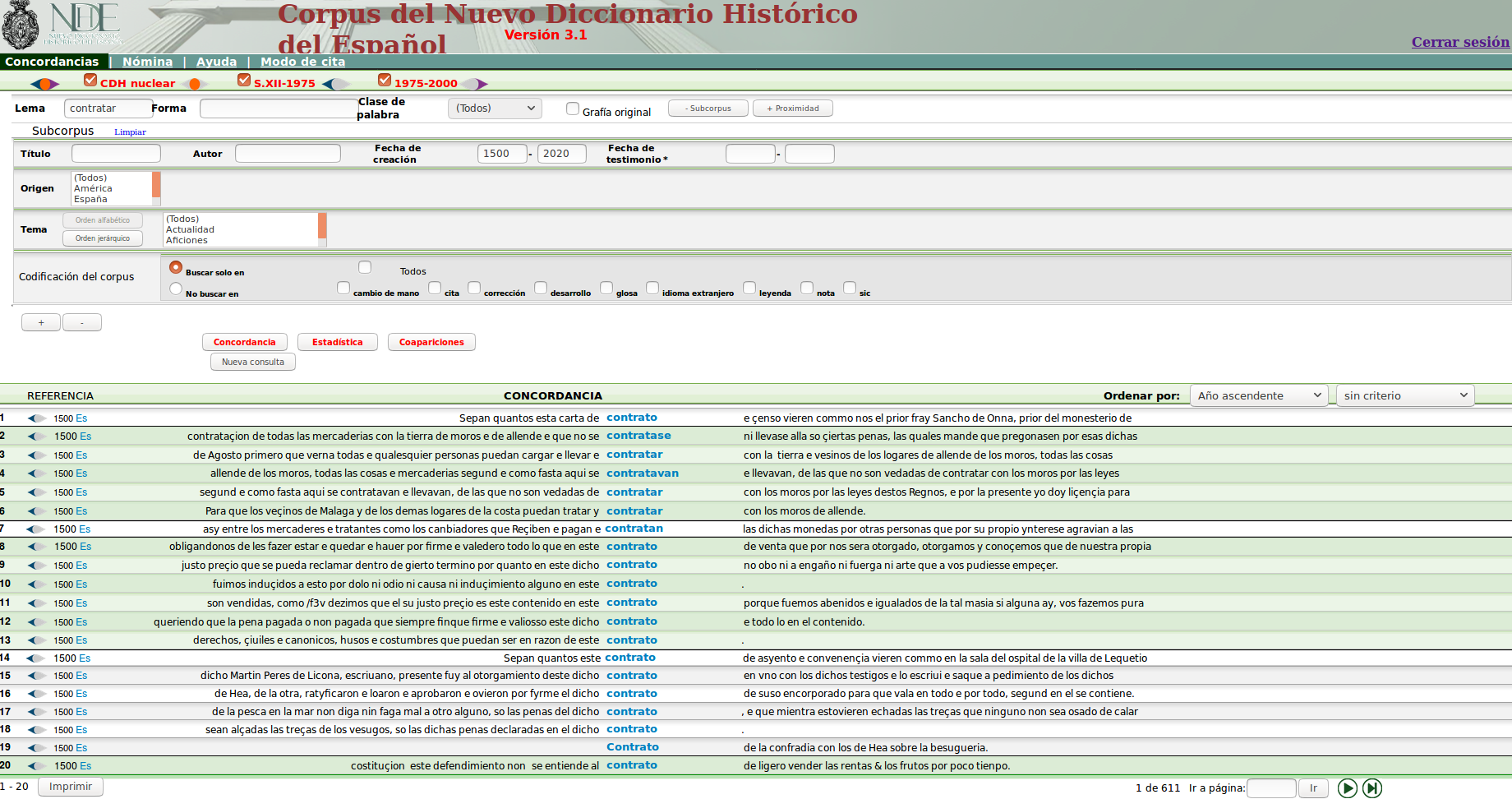
- Die dem Projekt zugrundeliegende Daten wurden von der Webseite des Corpus del Nuevo Diccionario Histórico del Español extrahiert.
- Automatisch wurden Sätze, die ein gesuchtes Lemma enthielten, gesucht und in Form einer HTML-Datei gespeichert (Ein Ausschnitt einer solchen Datei ist unten zu sehen).
Vorverarbeitung
Zunächst wurden aus den HTML-Dateien saubere XML-Dateien generiert, wofür wir ein selbstentwickeltes Python-Programm verwenden.
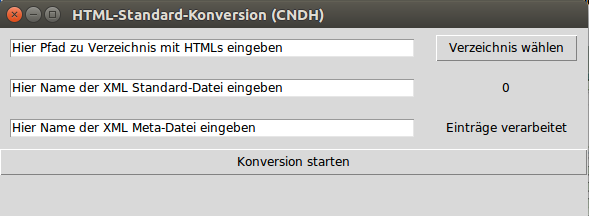
Einerseits werden dabei die Korpus-Dateien generiert, die den Text enthalten, andererseits Dateien, welche die Metadaten enthalten. Mit einem Tagger wurden die Texte ausserdem tokenisiert und getaggt. Der Tagger basiert auf der gratis verfügbaren FreeLing-Plattform (Link).
XML-Struktur
Die saubere, getaggte XML-Datei sieht schliesslich so aus (Ausschnitt):
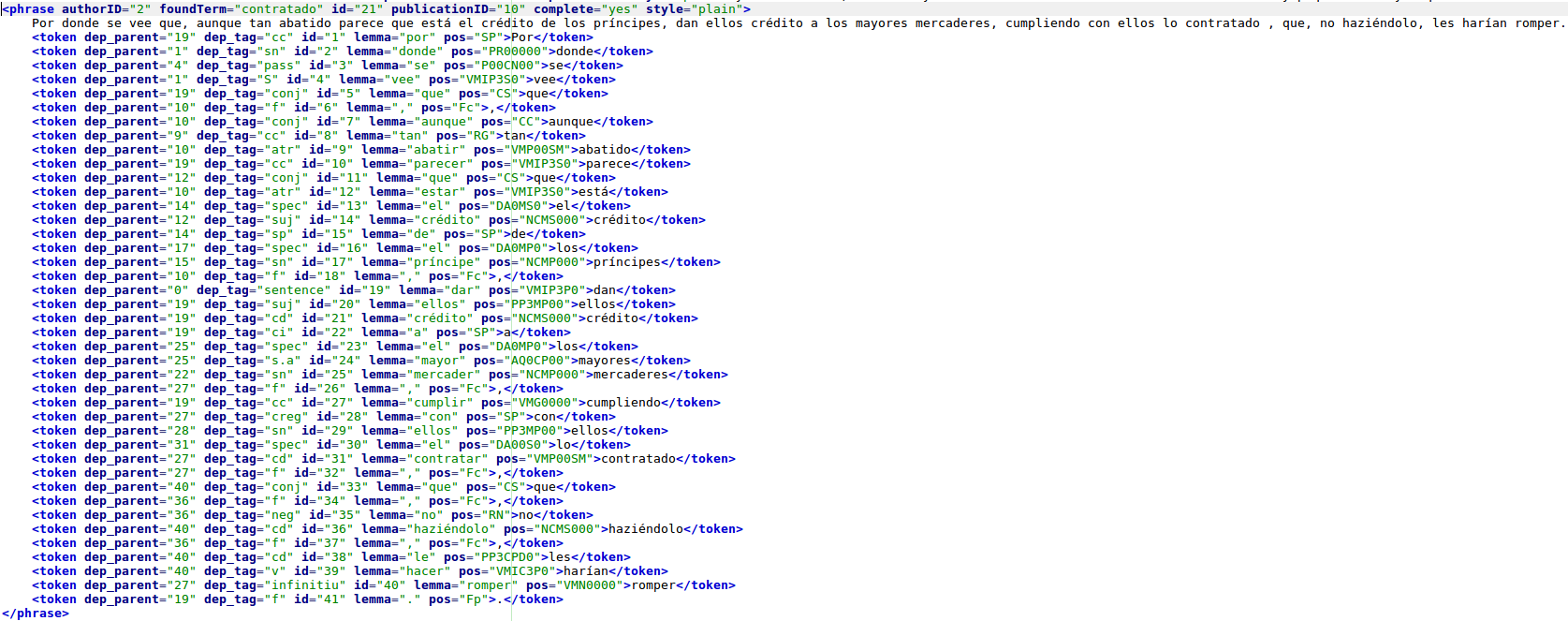
Dazu sind die Metadaten in einer separaten Datei festgehalten (publicationID und authorID verlinken die Datensätze):

Korrektur und weitere Annotation
Jeder Datensatz wird manuell nochmal durchkorrigiert. Dazu wird die XML-Datei mit dem Python-Programm zu einer Webanno-Importdatei umgewandelt, welche dann zu Webanno importiert wird.
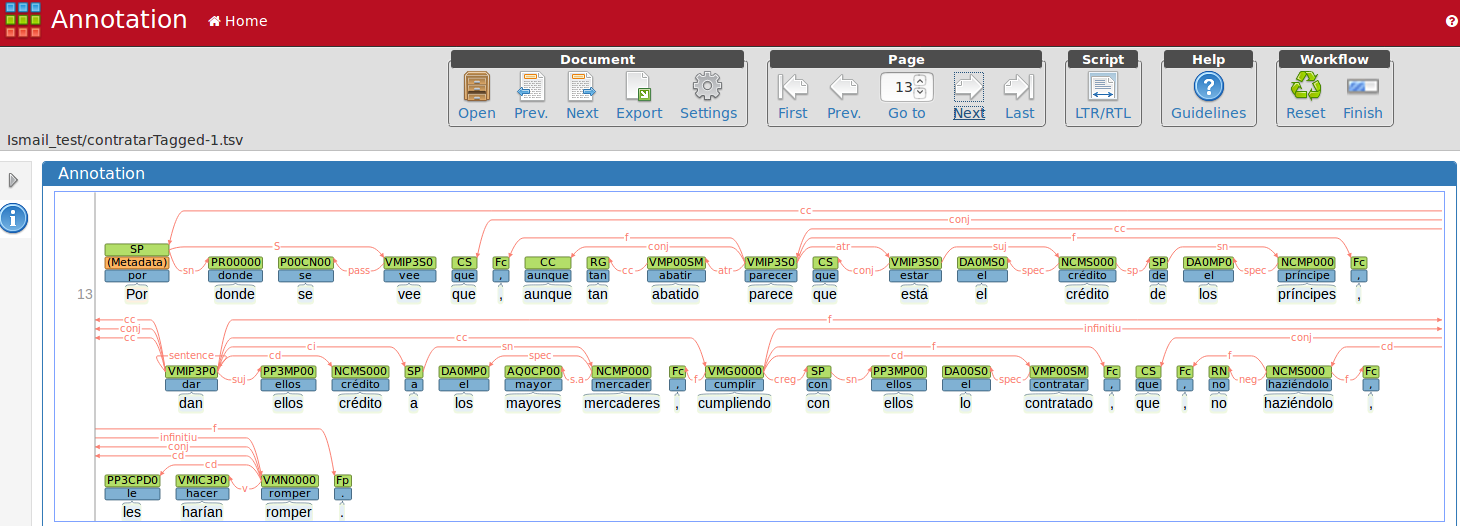
In dieser Oberfläche kann nun jeder Satz einzeln korrigiert oder mit weiteren Annotationen versehen werden. Ist die Korrektur/Annotation abgeschlossen, wird eine Webanno-Datei exportiert, die wieder zur eigenen XML-Struktur konvertiert wird.
Auswertung
Zur Auswertung der Daten bedienen wir uns wiederum eines eigenen Python-Skriptes, welches es ermöglicht, nach ganz bestimmten Wort-, POS- oder Dependent-Kombinationen zu suchen.
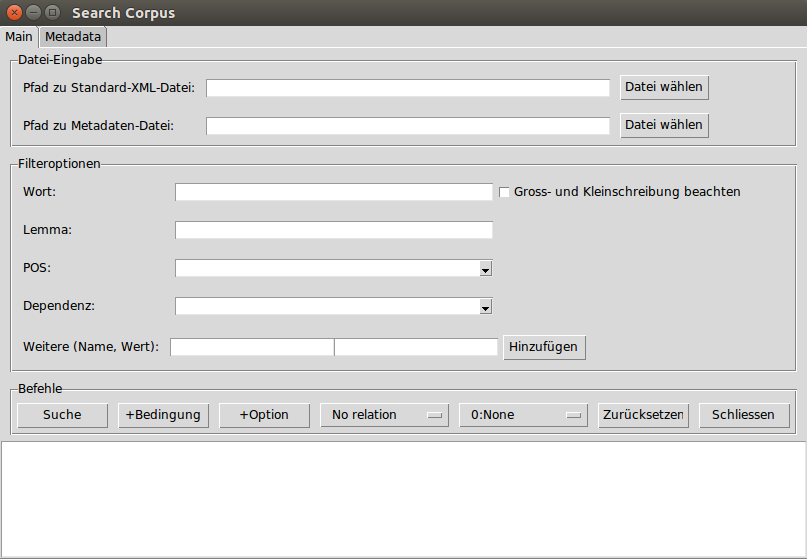
Es ist auch möglich, die Suche auf bestimmte Jahre, Autoren, usw. zu beschränken. Die Suche gibt zwei Dateien aus: Erstens eine HTML-Datei, in der die Suchergebnisse dank Markup deutlich angezeigt werden können. Zweitens eine XML-Datei, die der Standard-Struktur entspricht, aber auf die gefundenen Sätze beschränkt ist.
Die gefundenen Daten können dann von Hand weiter ausgewertet und verglichen werden.
Visualisierung
Die gefundenen Daten können mit R und googleVis schliesslich auf Motioncharts dargestellt werden.
{kind=link}